
Uncertainty Intervals
By default Prophet will return uncertainty intervals for the forecast yhat. There are several important assumptions behind these uncertainty intervals.
There are three sources of uncertainty in the forecast: uncertainty in the trend, uncertainty in the seasonality estimates, and additional observation noise.
Uncertainty in the trend
The biggest source of uncertainty in the forecast is the potential for future trend changes. The time series we have seen already in this documentation show clear trend changes in the history. Prophet is able to detect and fit these, but what trend changes should we expect moving forward? It’s impossible to know for sure, so we do the most reasonable thing we can, and we assume that the future will see similar trend changes as the history. In particular, we assume that the average frequency and magnitude of trend changes in the future will be the same as that which we observe in the history. We project these trend changes forward and by computing their distribution we obtain uncertainty intervals.
One property of this way of measuring uncertainty is that allowing higher flexibility in the rate, by increasing changepoint_prior_scale, will increase the forecast uncertainty. This is because if we model more rate changes in the history then we will expect more in the future, and makes the uncertainty intervals a useful indicator of overfitting.
The width of the uncertainty intervals (by default 80%) can be set using the parameter interval_width:
1
2
3
# R
m <- prophet(df, interval.width = 0.95)
forecast <- predict(m, future)
1
2
# Python
forecast = Prophet(interval_width=0.95).fit(df).predict(future)
Again, these intervals assume that the future will see the same frequency and magnitude of rate changes as the past. This assumption is probably not true, so you should not expect to get accurate coverage on these uncertainty intervals.
Uncertainty in seasonality
By default Prophet will only return uncertainty in the trend and observation noise. To get uncertainty in seasonality, you must do full Bayesian sampling. This is done using the parameter mcmc.samples (which defaults to 0). We do this here for the first six months of the Peyton Manning data from the Quickstart:
1
2
3
# R
m <- prophet(df, mcmc.samples = 300)
forecast <- predict(m, future)
1
2
3
# Python
m = Prophet(mcmc_samples=300)
forecast = m.fit(df, show_progress=False).predict(future)
This replaces the typical MAP estimation with MCMC sampling, and can take much longer depending on how many observations there are - expect several minutes instead of several seconds. If you do full sampling, then you will see the uncertainty in seasonal components when you plot them:
1
2
# R
prophet_plot_components(m, forecast)
1
2
# Python
fig = m.plot_components(forecast)
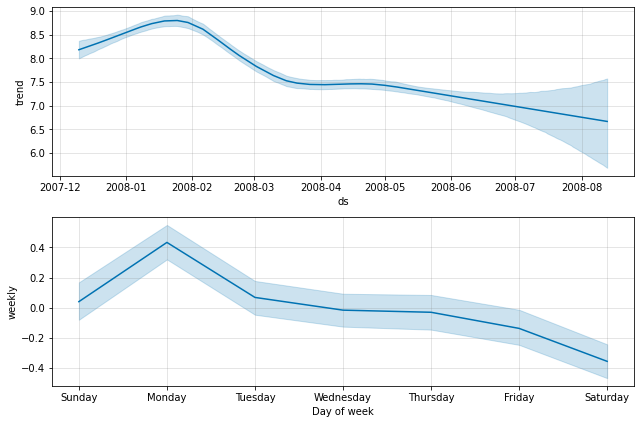
You can access the raw posterior predictive samples in Python using the method m.predictive_samples(future), or in R using the function predictive_samples(m, future).